开发
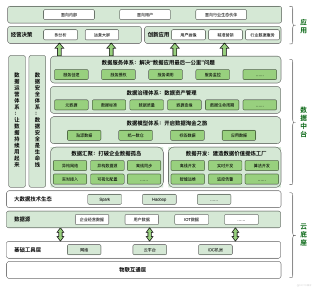
呕血总结:「大数据技术体系」学习实践导览
导言 截止目前为止,在自己的技术生涯中,要说哪一种技术体系的学习路径最为曲折,那非大数据技术体系莫属了。相比特定编程语言的学习,相比类如云原生技术这类已然涵盖面很广的技术体系,个人感觉大数据技术的体系
开源交流丨一站式大数据平台运维管家ChengYing安装原理剖析
本期我们带大家回顾一下漫路同学的直播分享《ChengYing 安装原理剖析》。 本期内容多为实战演示,欢迎有兴趣的同学去 B 站配合视频观看,便于理解。 一、ChengYing 安装原理 ChengY
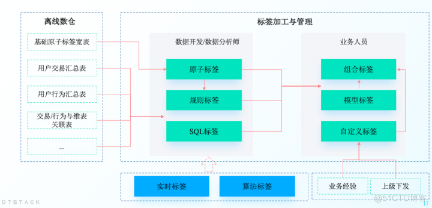
终于有人把不同标签的加工内容与落库讲明白了丨DTVision分析洞察篇
上一篇文章详细给大家介绍了标签的设计与加工,在标签生命周期流程中,标签体系设计完成后,便进入标签加工与上线运行阶段,一般来说数据开发团队会主导此过程,但我们需要关心以下几个问题: ・标签如何快速创建和
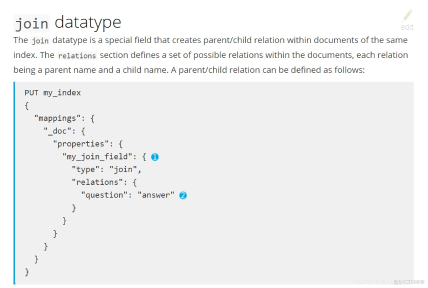
实战Elasticsearch6的join类型
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 《Elasticsearch实战》(英文名E
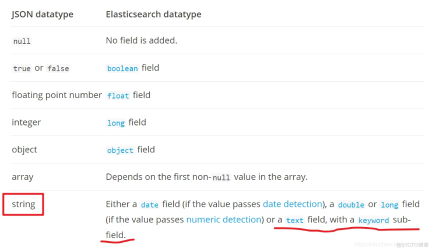
elasticsearch的字符串动态映射
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 映射用来定义文档及其字段如何被存储和索引,文档写入es
Spark面试题——Spark容错机制
问过的一些公司:头条, 字节,阿里 x 3,腾讯,竞技世界 参考答案: 1、容错方式 容错指的是一个系统在部分模块出现故障时还能否持续的对外提供服务,一个高可用的系统应该具有很高的容错性;对于一个大的
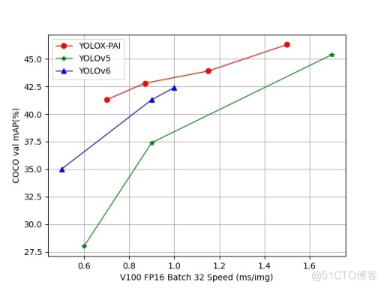
YOLOX-PAI: 加速 YOLOX, 比 YOLOV6 更快更强
作者:忻怡、周楼、谦言、临在 导言 目标检测(object detection)旨在定位并识别出图像中的目标物体,一直以来都是计算机视觉领域研究的热点问题,也是自动驾驶、目标追踪等任务的基础。近年来,
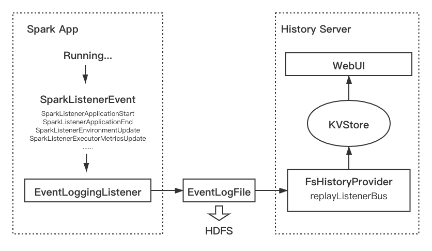
提速 10 倍!深度解读字节跳动新型云原生 Spark History Server
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 前不久,在 6月29日 Databricks 举办的 Data + AI Summit 上,火山引擎向大家首次介绍

(1)sparkstreaming结合sparksql读取socket实时数据流
Spark Streaming是构建在Spark Core的RDD基础之上的,与此同时Spark Streaming引入了一个新的概念:DStream(Discretized Stream,离散化数据
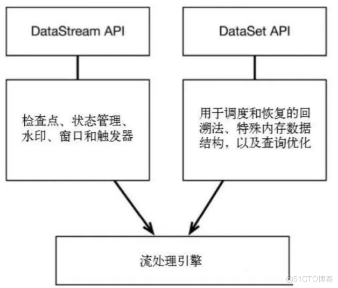
大数据面试题——Flink面试题(二)
1 Flink是如何支持批流一体的? 本道面试题考察的其实就是一句话:Flink的开发者认为批处理是流处理的一种特殊情况。批处理是有限的流处理。Flink 使用一个引擎支持了DataSet API 和
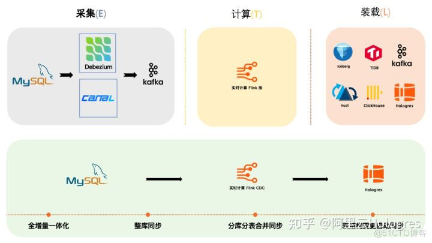
阿里云 Flink+Hologres:构建企业级一站式实时数仓
作者|徐榜江 余文兵 赵红梅 随着大数据的迅猛发展,企业越来越重视数据的价值,这就意味着需要数据尽快到达企业分析决策人员,以最大化发挥数据价值。企业最常见的做法就是通过构建实时数仓来满足对数据的快速探
Linux环境变量 & 进程地址空间
写在前面 这个博客主要谈一下环境变量和程序地址空间,其中程序地址空间可能有点不好理解,但是这个可以帮助我们解决前面我们遗留的一些问题,以后我们几乎都要和程序地址空间打交道,很重要.当然,前面的环境变量
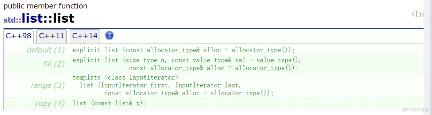
list学习 & 模拟
写在前面 到这里我们就知道知道STL的具体的框架了,里面的一些函数你会发现用法都一样。这个博客主要谈一下迭代器的分封装,前面我们蹙额的string和vector的迭代器都是原生指针,但是今天的却不一样
docker下的spark集群,调整参数榨干硬件
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是《docker下,极速搭建spark集