伴随着国家产业升级的推进和云原生技术成熟,多点 DMALL 大数据技术也经历了从存算一体到存算分离的架构调整变迁。本文将从引入 Kyuubi 实现统一 SQL Proxy 的角度讲述这一探索实践的历程。
多点 DMALL 成立于2015年,提供一站式全渠道数字零售解决方案 DMALL OS,目前已与130+连锁零售企业、近1000家品牌达成合作,覆盖5个国家和地区。作为一站式全渠道数字零售解决方案服务商,多点 DMALL 通过数字化解构重构零售产业,提供端到端的商业 SaaS。方案整体涵盖了从商品选择、供应商引入、仓储供应链管理、门店经营、用户精准营销的整个产业链,实现了人人、事事、物物在线。
Apache Kyuubi 是网易数帆发起开源的一个分布式和多租户网关,用于在 Lakehouse 上提供 Serverless SQL,社区目前已聚集海内外百余名贡献者。
作为 DMALL OS 数字化能力的技术底座,大数据平台历经多次迭代平稳支撑了公司 To B 业务的开展。伴随着国家产业升级的推进和云原生技术成熟,多点 DMALL 大数据技术也经历了从存算一体到存算分离的架构调整变迁。本文将从引入 Kyuubi 实现统一 SQL Proxy 的角度讲述这一探索实践的历程。
技术背景
行业技术发展趋势
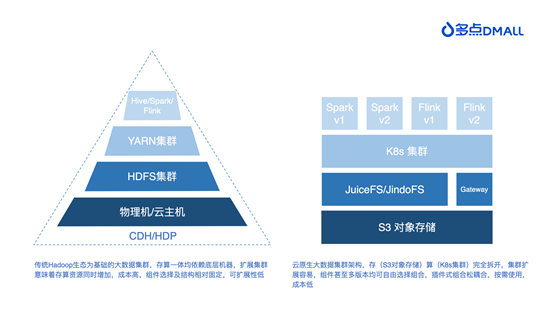
第一代的大数据技术主要采用传统 Hadoop 开源技术栈,几乎所有的企业搭建大数据集群都是从 HDFS、Hive 和 YARN 开始的。除了 Apache 开源组件组合外,许多企业也会选用 CDH、HDP 等商业发行套件,方便运维和部署。随着技术的成熟,传统的 Hadoop 技术开始暴露一些缺点:
1. 部署运维成本高
Hadoop 生态组件所需基础硬件资源较多,组建集群时需要慎重设计和调整,部署成本高,后期运维复杂度高。
2. 集群隔离,资源浪费
大数据集群部署时常常需要单独申请机器,与业务服务集群资源隔离。总体来看,两个集群的潮汐现象都存在,大数据集群白天较为空闲,业务服务集群夜间用户使用量低,隔离部署的方式会产生较大资源浪费。
3. 存储成本持续升高
大数据集群的数据量是一直增长的。纵使企业做了冷热分离的设计、定时归档的处理,也只是减缓了增长趋势,依旧无法解决存储成本一直升高的现状。当然,除了上述缺点,还有 NameNode 元数据压力过大、组件版本相互制约等问题。这些缺点对于企业内部使用尚且可以优化处理,但是作为一家需要为客户提供定制化服务的企业,尤其面对日益突出的“性能”、“成本”、“安全”、“稳定性”等核心问题,多点 DMALL 意识到必须做出改变。
To B 的大数据平台建设趋势
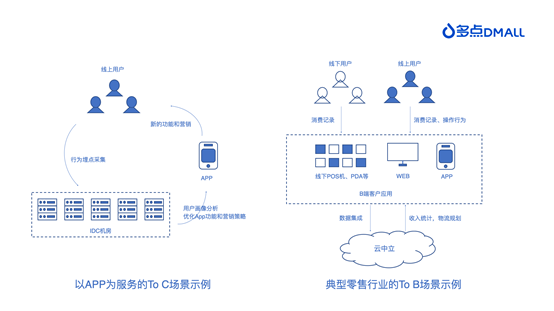
To B 的企业商业逻辑和 To C 的差别很大,在大数据领域的差别更大。
1. 精细的成本管理
To C 的大数据平台使用者多是企业内部员工。使用大数据平台产生的成本单独计算,个人用户不会为这些资源消耗直接买单。但在 To B 模式下,使用者基本都来自B端企业客户,客户要为其资源使用付费。这就意味着作为服务提供商需要精细化成本,尽最大可能降低成本才能获得客户的认可。
2. 更低的使用门槛
企业内部使用的大数据平台,员工背景可控。To B 的大数据平台面对的环境要复杂很多。客户当前的信息化程度、员工技能等都不相同,大数据平台需要提供更多方式、更低门槛来帮助客户的使用。
3. 更快的交付效率
需要进一步简化技术架构和实现,采用标准化的手段小时级交付新环境,节省时间同时进一步降低后续运维难度。这样以后逐渐形成快速规模化复制的能力,输出零售数据中台解决方案。
多点 DMALL的大数据技术发展
上述技术背景和商业背景的发展,对多点 DMALL 的大数据技术基座持续提出更高的要求。在持续优化升级的过程中,多点 DMALL 的大数据集群架构经历了从传统Hadoop生态迈向云原生,从存算一体到存算分离的架构变迁。
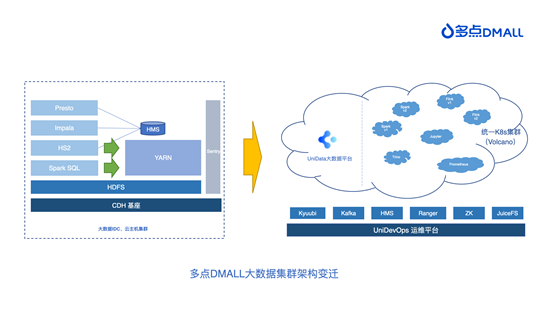
接下来,我们将详细讲述这一变迁的背景及其设计,以及 Kyuubi 在其中承担的角色和优化实践。
存算一体架构下的即席查询优化
架构背景
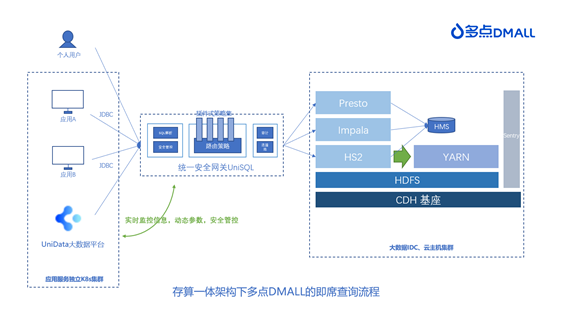
与其他大部分企业一样,多点 DMALL 最开始采用的是传统 Hadoop 技术栈构建数据中台 UniData,强依赖 CDH 发行版,采用 IDC 物理机/云主机集群部署。在即席查询中,我们采用自研的统一安全网关UniSQL连接用户和底层引擎。UniSQL 可为用户提供安全校验、血缘采集、SQL 审计、限流、白名单、查询降级、查询结果限制等平台管控级功能,最初只支持对接 Impala 和 Hive 查询引擎。很明显基于查询速度的优势,平台用户会优先选择 Impala 作为查询引擎。随着平台的推广和用户量的增加,我们发现这样的架构存在不少问题。
1. Impala 资源紧张
Impala 的资源紧张现象越来越频繁,因其本身资源隔离较为复杂,也没有 HiveServer2 提供的原生查询条件控制等,使得整体可用性降低。虽然我们在优化中通过平台层面补救进行部分 SQL 的拦截,但是依然无法完全阻挡部分占用大量资源的 SQL 执行。
2. Hive 查询速度不佳
相比于 Impala,Hive 查询速度不佳,用户体验较差。一方面,MapReduce 任务会产生大量临时小文件,影响运维人员的判断;另一方面,MapReduce 任务报错常常很隐晦,用户从 Hive 执行日志中无法直接获取,需要运维人员去 YARN 管理页面搜索查询详细信息,带来较大的运维成本。
3. YARN 集群潮汐现象严重
如图所示,YARN 所在的集群是为大数据独立搭建的基于 IDC/云主机的集群。实践中发现,YARN 集群的潮汐现象非常明显,凌晨时分伴随着大量离线任务的启动,集群资源非常紧张;白天任务量很少,Impala 的大量使用意味着 Hive 查询量少,集群总体使用量较为空闲。基于上述的原因,我们考虑引入 SparkSQL 作为即席查询的另一个可选项,在Impala资源紧张时,将Impala的查询资源引导入 YARN 集群中,同时减少 Hive 的查询以提升用户整体的查询速率。选型过程中 Kyuubi 进入了我们的视线。
架构设计
事实上,这不是我们第一次调研 Kyuubi。早在 Kyuubi 正式开源时,我们便尝试引入Kyuubi 作为多租户代理工具,正巧赶上当时公司技术发展方向的优先级调整,这一尝试暂时搁置。后来在需求的驱动下,我们开始重新引入 Kyuubi,这时 Kyuubi 已经到了1.5.2版本。现行的架构已经稳定在多个集群运行,为了尽可能减少架构调整,保证引入过程中集群其他任务及服务的稳定性,最终引入 Kyuubi 后即席查询涉及的总体架构图如下:
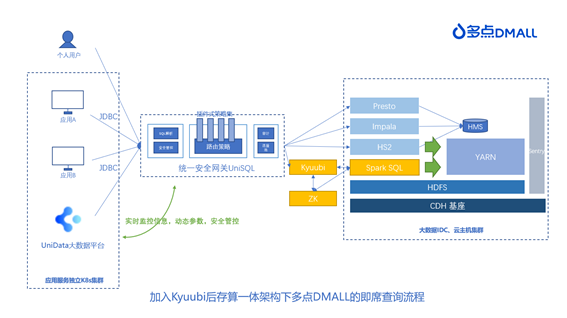
优化探索
线上环境中已经有 UniSQL 作为统一安全网关,Kyuubi 所承担的角色仅聚焦于多租户的 Spark SQL 代理。为了适配其他底层组件等原因,我们对 Kyuubi 进行了部分调整:
1. 在现有的 CDH 环境下,为了匹配 Sentry 的权限管控和 YARN 的资源调度,我们修改了 Kyuubi 提交 Spark 的执行命令,不使用 proxy-user 和 -queue 的参数,直接切换用户提交;
2. 由于安全组件使用 Sentry 进行权限管控的,在网上也没有开源产品可以提供SparkSQL 基于 Sentry 的校验,我们只好单独适配实现了针对 Sentry 的 Spark Extension;
3. 基于 Kyuubi 提供的 kyuubi.engine.initialize.sql 参数,将我们原来为 Hive 和Impala 提供的 UDF 迁移到 SparkSQL 服务中,Kyuubi 在初始化 Spark 时便自动加载对应的 jar 包和 Function,用户切换引擎时使用无感知;
4. 为了方便用户从 Impala 切换到 Spark SQL 查询,我们定制化支持了部分 SQL 语法,例如 invalidate metadata 进行元数据主动刷新等;在用户的使用中,我们也进行了一系列参数优化。例如设置 spark.files.overwrite=true方便部分用户重复提交 jar 包以及测试自定义 UDF 函数;设置 spark.sql.autoBroadcastJoinThreshold=-1 关闭自动 Broadcast 以提高稳定性等。
遗留问题
在原有架构中,我们以最简单的方式引入 Kyuubi,为客户提供了另一种查询引擎的可能,但是这样的引入很明显存在其短板:
1. JDBC 链路太长
用户从发起的 JDBC 连接到最终开始执行 SQL,中间需要分别经过 UniSQL 和 Kyuubi服务。多个连接池的管理提升了总体的连接管理复杂度,在报错时更是不易分析查找。有赖于 Kyuubi 和 UniSQL 的稳定,在实际使用中暂未发现因多个连接池连接导致的严重影响,但风险和隐患依旧存在。
2. SQL Proxy 角色重叠
同为 SQL Proxy,UniSQL 和 Kyuubi 的角色存在重叠,很明显这样冗余的设计并不利于未来架构的发展。
3. Spark 版本不统一
基于历史原因,现有架构中我们为用户提供的是 Spark 2.4.6和 Spark 2.3.1版本,但是Kyuubi 是需要搭载 Spark 3.x版本。引入 Spark SQL 查询,又不能贸然将之前的版本“一刀切”,我们只好暂时单独为 Kyuubi 部署 Spark3.x 版本。这就造成现在集群中存在不统一的 Spark 版本,增加运维的难度。
4. Zookeeper 版本不统一
我们使用的 CDH 发行版版本为5.16.2,搭载版本为3.4.5的 Zookeeper。Kyuubi 的 HA 同样需要依赖 ZooKeeper,但是经过我们测试,使用3.4.5的 Zookeeper 会出现删除节点失败的情况,从而导致 Kyuubi Server 自动关闭。经过分析,这一 BUG 在更高版本中修复完毕。最终,我们只好单独部署3.6.1版本的 Zookeeper 供 Kyuubi 使用。
5. Sentry 权限与 Spark 的对接不易
CDH 限定了集群的权限管理服务为 Sentry。众所周知,Sentry 的设计架构简单,缺失更细粒度的权限控制,包括视图、行、列等。而且 Spark 没有原生支持 Sentry 的权限管控方式。虽然我们开发了针对 Sentry 的 Spark Extension 进行权限管控,更细粒度的管控依旧是我们很头疼的地方。
存算分离架构下的统一 SQL Proxy 实践
架构背景
随着多点 DMALL 全面 To B 转型,为越来越多的B端客户提供零售全渠道解决方案,需要具备在多云部署环境下提供更具性价比、可复用的大数据底层基座和平台工具链。我们也终于等到了一个契机,彻底甩开历史包袱,设计搭建存算分离、轻量级、可扩展、云中立大数据集群架构。
幸运的是,Spark on K8s 的技术趋于成熟,我们得以全面拥抱云原生。在 K8s 的基座上,我们合并了大数据计算集群和业务服务集群,甩开 CDH 的版本限制,剥离 Hadoop 生态的强依赖,充分利用对象存储,简化运维和部署,降低用户使用成本。
考虑到上一版架构中的部分遗留问题,在升级架构设计中,经过详细的调研、分析和选型,Kyuubi 也正式替换 UniSQL 作为 SQL Proxy,负责多套查询引擎的统一代理服务。
升级架构设计
在升级架构中,我们充分考虑到之前版本不一致的情况,合并并简化了技术选型,使整体架构更轻量级和可扩展:
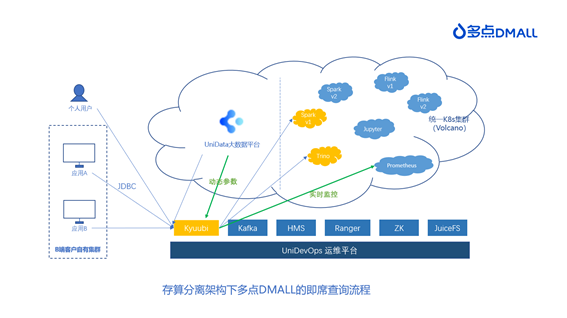
实践方案
使用 Kyuubi 作为统一 SQL Proxy,那么 Kyuubi 就需要满足之前 UniSQL 为代表的代理服务的全部辅助功能,包括审计日志、实时监控、限流、动态参数修改、权限管控等。因此我们深入学习了社区的实践经验和最优推荐,根据场景和需求,完善了 Kyuubi 的服务。以下为我们部分实践结果。
- SQL审计
作为统一代理层,需要对所有 SQL 和连接进行详细的记录,包括用户、SQL、执行时间、执行结果等。这样的数据并非实时使用,而是用于后续回溯查找问题,或者进行用户操作习惯的统计分析。幸运的是,Kyuubi 提供了 EventHandler 的方式,收集了非常完整的信息。在 Kyuubi1.6.1中,支持使用下列参数将相关记录落在本地日志中:
kyuubi.backend.server.event.json.log.path
kyuubi.backend.server.event.loggers
本地日志并不方便统计分析,我们需要更灵活的方式。最终我们选择仿照原生JsonLoggingEventHandler类,继承EventHandler自定义将所需日志写入 Kafka 中。后续再通过大数据平台的功能,落地到 Hive 或其他引擎中用于回溯分析。
- 实时监控
当前即席查询的使用情况如何、连接数量、失败原因等,都需要实时监控查看。Kyuubi 提供了非常完整的指标监控能力,我们也复用内部运维平台的监控体系,选用了 Prometheus + Grafana 作为实时监控的载体。
相关参数:
kyuubi.metrics.reporters
- 限流
不同平台和用户的使用方式不同,容易导致连接数爆发,从而影响 Kyuubi 服务的稳定性。因此,限流是必须要纳入考虑的。Kyuubi 提供了部分参数进行限流:
kyuubi.server.limit.connections.per.user
kyuubi.server.limit.connections.per.ipaddress
虽然这些参数限制到了单用户的连接数,甚至单用户单 IP 的连接数,但是这些参数是对所有用户统一的,而且 Kyuubi 服务启动后不能动态修改。就我们的使用经验来看,支持针对不同用户动态设置不同的连接限制将是一种更灵活的方式。但当前的功能也能基本满足限流管控要求,最终决定针对这个场景我们不做代码修改,期待社区未来能够提供更精细的管控功能。
- 参数动态传递
线上环境缺乏合适的方式进行参数传递,这个遗憾在新的架构中得以弥补。通过 Kyuubi提供的自定义动态参数传递方式,实现SessionConfAdvisor类后对接配置中心。参数将在每次启动Session的时候动态拉取,也能较好的满足不同用户不同资源分配的场景:
kyuubi.session.conf.advisor
当然,为了减少对不同环境参数的自定义jarb包管理,我们调整了传入该类的参数,添加了KyuubiConf,这样不同环境部署的 Kyuubi 自动可以传入对应的配置中心路径等信息,自定义的 jar 包也可以环境无关,减少代码运维的复杂度。
- 基于 Ranger 的权限校验
甩开了 CDH 对于 Sentry 的强制要求,新的架构选用 Ranger 进行权限管控。因此可以直接使用 Kyuubi 提供的 auth-extension 进行权限校验。不过为了提升整体的鉴权效率,我们重新设计了鉴权体系,将鉴权能力集中在新的鉴权服务 RAC 中,避免每一个 Spark 任务都在 Driver 本地落地一份 Ranger 权限策略。在这样的思路下,对于 Kyuubi 提供的 auth-extension 也做了适配性的修改。不过这不影响这个工具的便捷性:
spark.sql.extensions=org.apache.kyuubi.plugin.spark.authz.rangerRangerSparkExtension
只不过,就社区的更新速度来看,auth-extension 更新频率很高,我们在测试中发现了一些问题,包括视图权限、临时 Function 权限等问题,修复后都还没来及脱敏贡献给社区,社区就在 master 分支修复发布了。实话说,这也导致我们的这个插件更新非常痛苦,我们需要不断修改,不断适配。这也是我们越来越拥抱社区的原因,只要社区提供了功能,经过测试后我们便删除自定义代码,方便未来更新,也是尽可能跟着社区一起成长吧。
- 自动合并小文件
Kyuubi 提供的自动合并小文件工具是纯开箱即用的,Spark3.3 版本主要依靠 rebalance 逻辑。经过我们的测试,同样的来源表,同样写出10个分区,写出文件从近2000个缩小到10个,落地时间也从7min 缩小到40s,不仅降低了集群元数据的压力,更有效提升了整体任务效率。
spark.sql.extensions=org.apache.kyuubi.sql.KyuubiSparkSQLExtension
- 查询条件限制和扫描分区数限制
即席查询中,绝大部分探索性的查询都不需要大量的数据,结果数据量过大会引起 Driver 的压力过大,从而影响查询的稳定性以及用户的体验。社区最新提供了 HTTP 的异步获取的方式,但是这样的方式涉及到上下游改动,还在性能测试中。
按照线上环境的经验,我们将结果条数限制为1000条,针对不同的场景,这个参数也可以动态修改,基本满足返回结果要求。
spark.sql.watchdog.forcedMaxOutputRows
Hive 支持限制查询 SQL 中分区表必须带分区条件的严格模式,Kyuubi 也提供了类似的功能,可支持控制扫描分区数的限制。只是控制扫描分区数对于不同场景的需要不同,我们还没有正式利用这个功能,需要在实践中动态添加参数使用。
spark.sql.watchdog.maxPartitions
- 服务日志切分
之前运维经验发现,Kyuubi 服务在 logs 下写入的服务日志一直增量写入,发现的时候单文件日志已经达到了 90G。新架构下我们吸取教训,修改了 log4j2.properties,将日志按大小和日期拆分,仅保留最近7天的日志,彻底解决这个隐患。
- 自由选择资源组
在公司的实际使用中,一个 user 是可以在多个 group 中的,按照 Kyuubi 原生的提供的以 group 为引擎隔离 level 的情况下,会默认取该用户的第一个 group。我们将其修改成了通过 JDBC 参数可以选择 group 的能力,当然也包括了安全性校验,不允许恶意使用不属于自己的 group。
- Volcano 调度器的模板文件
Spark 官方文档中针对 Volcano 的调度器使用参数如下:
spark.kubernetes.scheduler.name=volcano
spark.kubernetes.driver.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep
spark.kubernetes.executor.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep
spark.kubernetes.scheduler.volcano.podGroupTemplateFile=podgroup-template.yaml
其中,最后这个参数 spark.kubernetes.scheduler.volcano.podGroupTemplateFile 需要是本地的 yaml 文件。我们针对这个修改了提交命令,支持动态生成模板文件进行提交。
下一步探索方向
我们也在根据原始架构中用户的使用反馈,持续优化升级版架构的设计,不断调整打造存算分离、轻量级、可扩展、云中立的大数据集群。
根据使用反馈,我们下一步将重点关注以下优化点:
1. 单点引擎稳定性不佳,当一个 SQL 将该引擎查挂后,下次再查询会先报错后启动新的引擎。这对于用户的使用不太友好。经过研究社区里其他企业的分享,下一步我们将关注资源池模式和引擎高可用的设计,以提升用户的使用友好度。
2. 精细化成本管控是升级架构的重中之重,但是原生的 Spark SQL 无法将资源拆分到SQL 粒度。这里也是我们下一步需要重点突破的内容,为用户提供清晰的成本数据。
3. 大数据基座上除了我们提供的大数据平台产品外,常有其他业务系统申请直接使用大数据相关资源,最典型的就是 JDBC 链接。白名单将是我们需要重点实现的功能。除了用户登录校验外,还能验证来源平台,对使用来源做出限制。
总结来看,我们从 Kyuubi 正式开源时开始关注,到如今的1.6.1版本,越来越欣喜地发现,每次升级都会有新的功能补充和思考。我们也在升级中逐渐减少自定义代码,使用 Kyuubi 社区提供的新特性。我们会持续跟踪社区动态,并将实践经验反哺社区,参与推动 Kyuubi 的发展。