在今年的第七届中国开源年会上,StoneDB 团队在大数据分论坛发表了《HTAP 的下一步?SoTP 初探》主题演讲,在本次演讲中,我们首次正式对外阐释了“SoTP 数据库”的技术理念,本系列是演讲实录+小编补充版,权当抛砖引玉,供大家批评指正。由于内容比较多,本文为第一章节,主要讲讲我们提 SoTP 的背景:From Big to Small and Wide Data。
一、HTAP 的起源、流派和迷思
HTAP 起源
我们首先从起源讲起,不过由于是公开演讲,考虑到一些听众是小白,所以这里主要是从一个比较宏观的关系型数据库行业发展历史视角来看的,关于 HTAP 更具体的技术和商业的起源背景,可以看看 StoneDB 首席架构师李浩老师写的这篇文章:HTAP 的背景。
众所周知,图灵奖(Turing Award)算是计算机领域里最高的一个奖项,截至今日,因为在数据库领域有杰出贡献而获得图灵奖的只有四位,分别是:
- 查尔斯·巴赫曼(CharlesW. Bachman),1973 年获奖,设计并开发了网状数据库管理系统 IDS,推动了数据库标准的制定,包括网状数据库模型、数据定义和数据操纵语言的规范说明(通俗来讲,是他第一次提出了数据库这么个东西,可以说是咱们的祖师爷);
- 埃德加·弗兰克·科德(Edgar Frank Codd),1981 年获奖,提出了关系数据库模型(关系型数据库经久不衰,目前依然占据市场最多的份额);
- 詹姆斯·古瑞(James Gray),1998 年获奖,主要是在大型数据库和事务处理技术上的突破(重点研究如何保障数据的完整性、安全性、并行性,以及故障恢复,曾担任 VLDB 期刊的主编);
- 迈克尔·斯通布雷克(Michael Stonebraker),2014 年获奖,现代数据库系统的概念和实践方面的基础性贡献(领导了影响力巨大的奠基性数据库 Ingres 的开发,也是最早提倡发展列存数据库的大佬之一)。

除了这四位数据库界公认的大佬外,也有其他大牛,比如:
- 1988 年,为解决数据集成问题,IBM 的 2 位研究员 Barry Devlin 和 Paul Murphy,创造性地提出了数据仓库(Data Warehouse)的概念;
- 1992 年,比尔·恩门(Bill Inmon)给出了数据仓库的定义。数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理中的决策制定;
- 1993 年,E.F.Codd 提出 OLAP,以及 OLAP 12 条准则。
- ......
能看到,早些年的数据库界名人们,并没有太多中国人士,和操作系统一样,中国在这类基础软件上的起步和投入都不算太早,这也是数据库领域目前成为我国 35 个“卡脖子”技术之一的原因吧。
我这里要指出的是——相信那些在数据库界深耕数十年的朋友们应该早就感受到了——仿佛,自从上述这些大佬奠定了关系型数据库发展的总基调后,后续的几十年里,就再没看到什么轰动一时的创新了,或者说,影响力能达到以上这些人士的数据库专家学者也没那么多了。那段时间,关系型数据库的热点话题好像从百家争鸣陷入了一个相对沉寂的时期,当然,后面也断断续续有一些新的技术热点,不过,能像上面这些大佬一样直接奠定一个学科或者理论的,就比较少了。
万籁“俱寂”时,一家知名 IT 研究与顾问咨询机构的发声,给关系型数据库这个平静的池塘丢了颗巨石:2014 年,Gartner 正式提出了 HTAP 这个概念。
Gartner’s definition in 2014: utilizes in-memory computing technologies to enable concurrent analytical and transaction processing on the same in-memory data store.<br /><br /> Gartner’s new definition in 2018: supports weaving analytical and transaction processing techniques together as needed to accomplish the business task.
可以看到,Gartner 重点强调了使用内存技术实现 HTAP 的可行性,并表示 HTAP 将为巨大的业务创新创造机会,增量市场空间巨大。

一石卷起千层浪,陷入半沉寂的关系型数据库技术,好像迎来了春天。那个时候,商业智能(BI)已经开始广泛渗入到众多企业的营销业务体系里了,处理数据的业务分析部门对实时处理和运维最简化的需求越来越重要,HTAP 方案的提出自然迅速地引起了行业的强势关注,因为这玩意儿光是听起来就省心省力,诱惑很大。
我们正在做的 StoneDB,就是对标 Oracle MySQL HeatWave 的一款开源版实时一体化 HTAP 数据库。
HTAP 流派

上图是清华大学李国良教授团队梳理的 HTAP 数据库的发展时间线。我们这里再举几个大家耳熟能详的企业:像数据库巨头 Oracle 去年就推出了 MySQL HeatWave,没错,Oracle 官方已经明确表示了,做 HeatWave 的目的就是为了支持 HTAP,在最近的 Oracle CloudWorld 大会上还官宣了 MySQL HeatWave Lakehouse;Google 在 HTAP 上也动作频频,除了搞 F1 Lightning 以外,在今年 5 月 12 日的 Google I/O 2022 开发者大会还宣布了云原生 HTAP 数据库 AlloyDB for PostgreSQL;紧接着,所有云数仓都想打的知名厂商 SnowFlake 也在 6 月 14 日的用户大会 Snowflake Summit 2022 上官宣正式推出 HTAP 存储引擎 Unistore;数据库独角兽SingleStore(前身为 MemSQL) 也早就在 HTAP 领域上频频发声,顶会论文都发了。国际上的这些大厂和独角兽都在搞 HTAP,国内的更不用说了,阿里、百度、腾讯、华为、字节和众多新兴创业公司(包括咱们 StoneDB),以及老牌数据库厂商都开始宣传自己的一些产品可以实现或者主攻 HTAP。Gartner 之前在报告里预测说,到 2024 年,HTAP 数据库会被广泛用到各行各业中,现在看来,真的是有这种势头了。
显而易见,HTAP 这俩马车的车轮已经压在了数据库行业的历史轨迹上,正在滚滚向前,势不可挡。但是,随着越来越多的厂商正式加入赛道,对于 HTAP 架构的技术实现,自然产生了一些分化。
我们之前在文章《深度干货!一篇 Paper 带您读懂 HTAP》中有做介绍,这篇报告里提到,至少有四种不同的架构方式可以实现 HTAP。
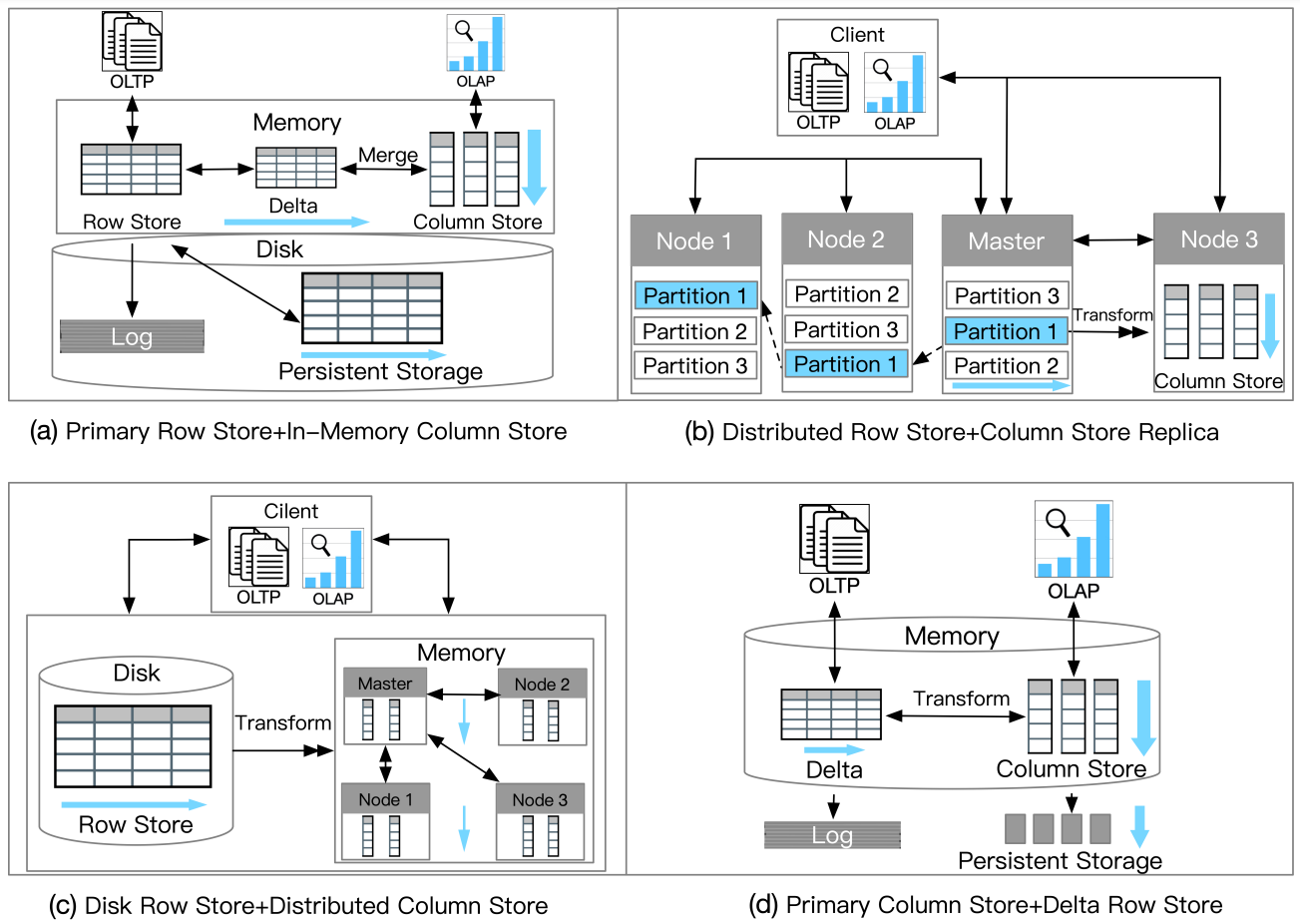
目前 HTAP 大致有四种实现方式:
-
方案 1(一套系统一套存储):在一个系统里用一种数据格式满足两种业务需求;
-
方案 2(一套系统两套存储):一个系统里同时存在行存储和列存储,行存储上的更新会定期导入到列存储里转换成列存储格式;
-
方案 3(两套系统两套存储):系统里同时存在 OLTP 与 OLAP 两套引擎,分别写入和读取行存储和列存储;
-
方案 4(多套系统松耦合):不同的异构系统之间,通过独立的插件服务对数据进行准实时同步,对外呈现 HTAP 能力。
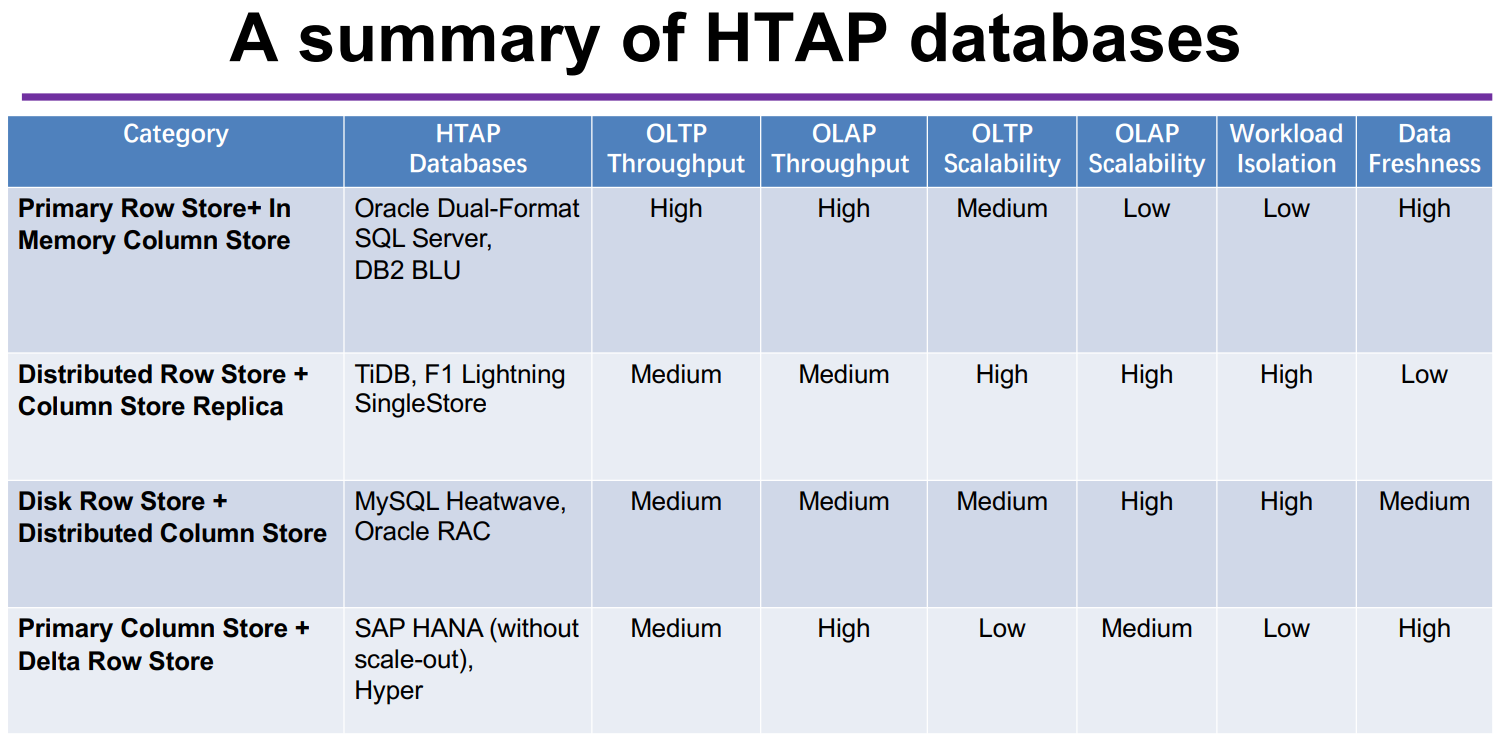
下面这张表图是我们对这四种架构方案的一个简单的综合盘点。

HTAP 迷思
随着一些 HTAP 产品功能能够实现落地了,在 HTAP 架构的选择上引起了不少争议(我们讲叫技术口水战),这很正常,大家都想说 HTAP 是自己做得比较好嘛。比如 StoneDB 这边就比较支持完全一体化的混合负载架构(我们称之为真正的 HTAP 面临的挑战);也有的团队比较想搞那种两套系统叠加的架构;还有更猛的,直接说要基于 GPU/CPU 搞 HTAP,就是 RateupDB,据说是全球唯一一个基于 GPU/CPU 和并行的 HTAP 数据库,还发了一篇 VLDB,不过好像现在销声匿迹了,创始人目前应该是投身一家势头较猛的云数仓创业公司去了。
由此可见,HTAP 虽然引起了一阵狂欢,但是,对 HTAP 数据库架构选择目前业界还是没有一套特别称得上成熟的方案,大家也都是在打磨产品中。有的走的稍微早了一些;有的还在孵化打磨;有的已经倒在半路上了,但是一个不可否认的事实是,大家都开始说自己能或者即将能支持 HTAP 了,就和数据库领域另外一个爆火的“云原生”关键字一样,这真可谓是“二四八月乱穿衣”了,这也算是现在 HTAP 领域上存在的迷思吧。
新的趋势:From Big to Small and Wide data
所以,在这个时候,作为率先提出要做 MySQL 开源 HTAP 数据库的 StoneDB,想要稍微冷静一下。
不是说我们不做 HTAP 了,而是有了一个新的思路。这个思路,也同样来自于咱们的老朋友、好伙伴,大家都巴不得上他们报告的权威机构——Gartner。
Gartner 在去年发布的《Gartner 2021 十大数据和分析趋势》报告里,特别提到了一个重要的趋势:。From Big to Small and Wide data

据 Gartner 预测,到 2025 年 70% 的组织会把重点从“大”数据转向“小”数据和“宽”数据,为分析提供更多的场景,使人工智能(AI)减少对数据量的需求(原文是 making artificial intelligence (AI) less data hungry)。

当然,这个趋势的调研结论是有背景的,那就是突如其来的新冠疫情。面对新冠,很多数据几乎是一夜式爆发式变化增长,导致了基于大量历史数据的机器学习和人工智能模型变得不那么可靠,随着智能决策变得更加复杂和严格,数据和分析领导者应选择能够更加有效利用现有数据的分析技术。
如何更加有效利用数据分析?那就是我们讲的用“小”而“宽”的数据取代“大”数据来解决问题。小数据——顾名思义,指的是能够使用所需数据量较少,但仍能提供实用洞见的数据模型。宽数据——可以理解为多模数据,即使用宽数据分析各种小而多样化的非结构化和结构化数据源并发挥它们的协同效果,从而增强情景态势感知(contextual awareness,情境感知)和决策。
下面就来详细讲解一下 Small Data 和 Wide Data 的定义。
Small data 概念
小数据的方法是指使用相对较少的数据,但仍能提供有见解的分析技术。其中包括了有针对性地使用数据要求比较低的模型,比如一些时间序列分析的技术,而不是用一刀切的方式去使用数据量要求较高的深度学习技术。
通俗地来讲,使用 AI 或者 ML 技术,往往需要大量的数据源作为分析的训练模型,但并不是数据量越多越好,特别是那些过时的历史数据,对分析毫无意义,如果可以及时地找到一些比较精准的小数据进行分析,往往能获得更有价值的效果。总之,小数据侧重于应用分析技术,在小量的、单独的数据集中寻找有用的信息。
Wide data 概念
宽数据允许分析师检查和组合各种大小、非结构化和结构化数据。具体来说,宽而广泛的数据就是将各种来源的不同数据源捆绑在一起,以进行有意义的分析。
基于宽数据的数据分析技术围绕着结构化和非结构化数据的分析和协同,而不管数据集是否直接相关。宽数据最大的特征是可以提取或识别异构数据集之间的联系。
Small and Wide data 结合的作用
Gartner 知名研究副总裁 Rita Sallam 表示:“使用‘小’而‘宽’的数据能够提供强大的分析和 AI,同时降低企业机构对大型数据集的依赖性。企业机构可以使用‘宽’数据获得更丰富、更完整的态势感知或 360 度视图,这将使企业机构能够使用分析技术做出更好的决策。”
Gartner 高级研究总监孙鑫表示:“随着企业逐渐认识到大数据作为分析和人工智能关键推动者的局限性,被称为小数据和宽数据的方法正在慢慢涌现,小数据的方法抛开了对于大型单体数据的依赖,实现了对于小型、大型、结构化、非结构化的数据源的分析和协同。”
同时,据 Gartner 预测,到 2025 年,超过 85% 的技术供应商,将在人工智能解决方案当中加入让数据变得更丰富的方法和模型训练技术,以提高模型的弹性和敏捷性,而在 2020 年,这样做的供应商只有不到 5%。 由此可见,小数据和宽数据的市场增量巨大。
Small and Wide data 核心场景
说了这么多“小”数据和“宽”数据,这两个到一块儿究竟能落地到什么应用场景上?
从一个具体的场景为例,现在电商以及社交媒体都在做一个实时推荐的业务场景,而实时推荐的标准流程是首先通过大数据系统对客户的购买历史进行分析,要关注客户购买产品的生命周期,客户与企业之间的交互历史;同时要去通过各种渠道去了解,目前客户正在什么环境,听到了什么? 正在浏览什么信息?结合各种数据进行分析,最后产生 Top10 的产品推荐,然后通过 App 或者其他手段推送给客户。
在这个过程中,需要收集的数据非常庞大,包括各种结构化数据,例如历史订单,客户个人信息等,另外客户的上网日志,网页浏览历史,客户的位置信息, 行动轨迹,这些数据的体量都非常大,而一旦涉及到千万乃至上亿的用户,同时上万种产品的场景下,这个数据量就是天文数字,而等待所有这些数据都收集完整并进行 AI 建模预测,则很可能是 1-2 天之后的事情了。
所以,为了尽可能快地对客户当前状况进行反馈,并推出相应的推荐方案,必须把数据链条缩短:首先通过在生产系统端,贴合用户的购买历史和行为,对整个场景进行约束,从海量数据分析,变成小数据量的分析,把推荐产品从几万,缩小到几十的范围,这个时候,就是从大数据到“小”数据的过程。然后在此基础之上,通过补足其他渠道的信息,包括图像、声音、浏览日志等等,对几十的范围进行进一步的精准化定位。这个时候,则体现了“宽”数据的价值。
预计小数据和宽数据技术将产生积极的结果,即:
- 零售需求预测(Retail demand forecasting)
- 实时行为智能( Real time behavioral intelligence)
- 超个性化和整体客户体验的改善( Hyper personalization and improvement of the overall customer experience)
- 人生安全
- 欺诈检测
- 自适应自动系统(比如自适应 AI)等等
虽然“小”数据和“宽”数据技术的确切结果还没有出现,但这个概念肯定是未来可期的,因为这些技术能够在过去或历史趋势不再相关的领域提供卓有成效的洞察分析能力。
对于从“大”数据到“小”数据的过程,一个趋势就是,数据分析不必一定从数仓开始, 而是从前端业务系统,结合一定的场景,首先发起快捷的数据分析, 解决场景定位,方案范围初筛等数据的初步处理,让后继的分析尽可能地聚焦在指定的领域,一方面减少计算量,同时加速后继决策的速度。
所以业务系统在承担业务交易的时候,必须增加一定的数据分析和筛选的能力, 这个和传统的业务系统是纯粹 OLTP 系统的定义不一样, 将来业务系统的能力将会从 OLTP 向 HTAP 逐步变迁。
这一块还有很多东西可以讲,后续我们继续探讨,今天就先点一下。作为在数据分析领域耕耘多年的数据库团队,我们对这个观点是非常认可的。因为,经常做数据分析的人都知道,随着使用数据的场景越来越多,数据支撑运营的场景也越来越多,很多情况下,数据驱动运营需要的是近期的热数据,而不是长时间的数据。而这个“热数据”,再更精确一些讲,就应该是“热”的“小”而“宽”数据。
这恰恰和 StoneDB 提倡的基于 MySQL 的 HTAP 数据库要能够支持实时与中小数据量场景不谋而合(正常 10T 左右,最高不超过 100T,当然了,要是扩展成 LakeHouse,支持的数据量会更多)。也和 SingleStore 讲的观点很类似:没有 HTAP,机器学习和人工智能都是不切实际的。
基于此,我们提出一个 idea,即 StoneDB 这种强调对热数据实时分析的 HTAP 数据库,也可以叫做 SoTP 数据库。
SoTP 初探
SoTP,即 Serving over TP。
Serving 是什么?SoTP 的定义和驱动又是什么?这个留给我们下一篇文章继续解读,欢迎关注 StoneDB 公众号。