直接截取网页全屏 截全屏的时候,我们用到的内置方法为save_screenshot("demo1.png"): from
selenium import webdriver from time import sleep
class test: driver = webdriver.Chrome() driver.maximize_window() driver.get('https://www.baidu.com/') sleep(2) # 截取全屏 driver.save_screenshot("demo1.png")
运行成功之后,打开截图文件,如下所示:
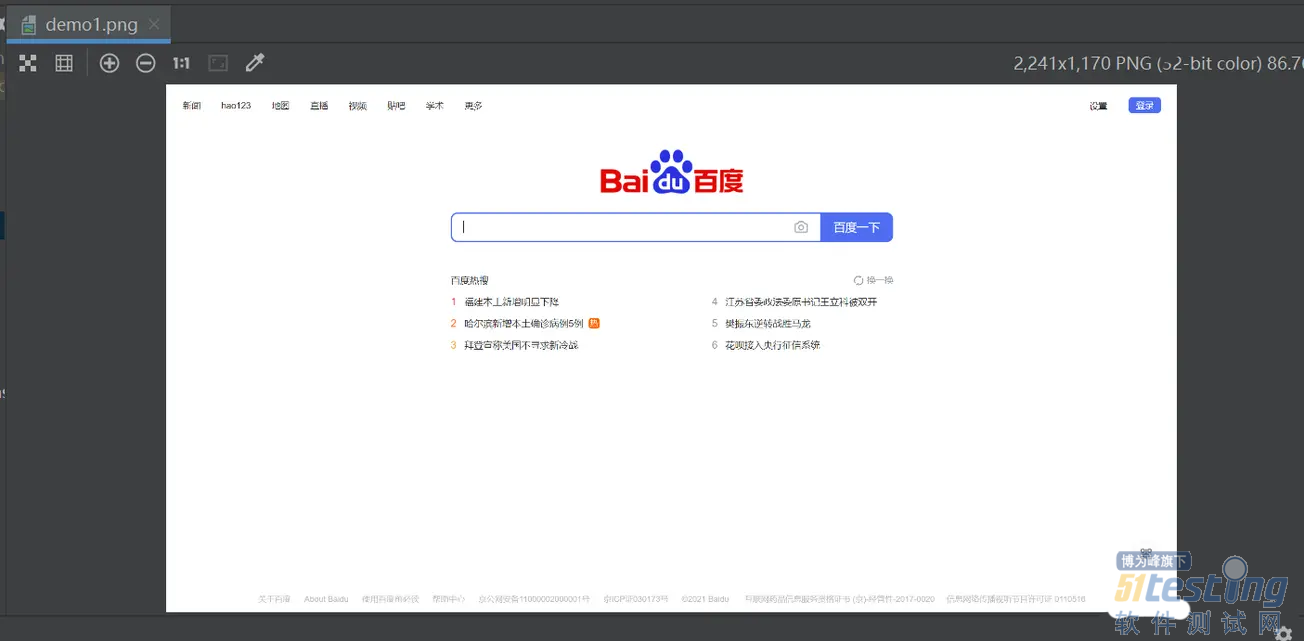
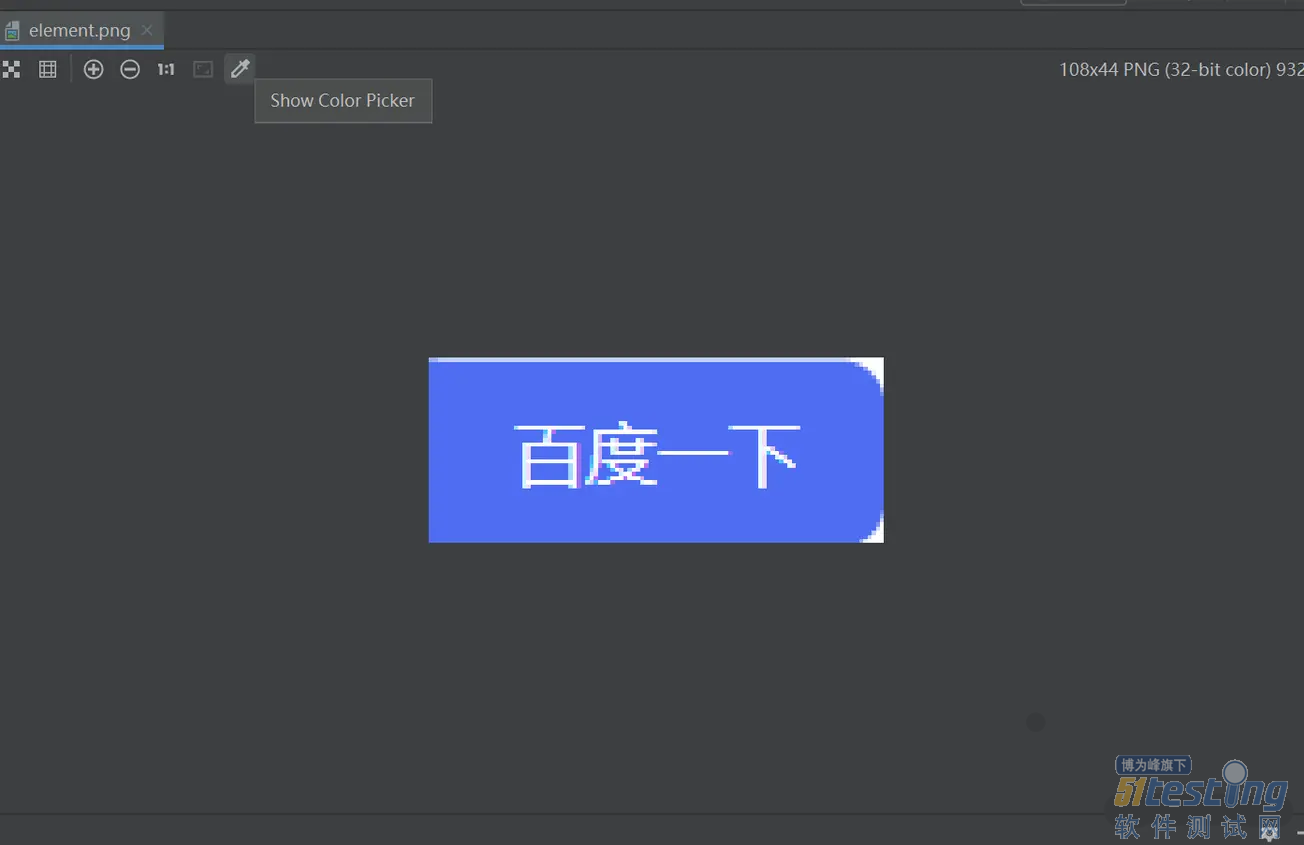
截取页面上固定元素的图片 咱们以截取
百度首页“百度一下”的按钮为例。 from selenium import webdriver from time import sleep
class test: # 打开
谷歌
浏览器 driver = webdriver.Chrome() # 网页全屏显示 driver.maximize_window() # 访问百度首页 driver.get('https://www.baidu.com/') # 强制等待2秒 sleep(2) # 使用ID定位的方法获取"百度一下"的元素 element = driver.find_element_by_id("su") # 截图 element.screenshot("element.png") # 关闭浏览器 driver.quit()
运行之后,打开图片文件,如下图所示:
截取指定位置的图片 from selenium import webdriver from time import sleep from PIL import Image
class test:
driver = webdriver.Chrome() driver.maximize_window() driver.get('https://www.baidu.com/') sleep(2) driver.save_screenshot("baidu1.png") element = driver.find_element_by_id("kw") print("获取元素的坐标") location = element.location print(location) print(element.size) # 计算元素上、下、左、右的位置 top = element.location['y'] bottom = element.location['y'] + element.size['height'] left = element.location['x'] right = element.location['x'] + element.size['width'] print(top, bottom, left, right) im = Image.open('baidu1.png') im = im.crop((left, top, right,bottom)) im.show() im.save("baidu2.png")
图片拼接 from selenium import webdriver from PIL import Image
driver = webdriver.Chrome() # 设置浏览器窗口最大化 driver.maximize_window() # 设置打开页面最大化,目的是更好的截取错误图 # 打开税网 driver.get("https://www.csdn.net/") # 1. 截取当前页面 driver.save_screenshot('result.png')
def join_images(png1, png2, size=0, output='result.png'): """ 图片拼接 :param png1: 图片1 :param png2: 图片2 :param size: 两个图片重叠的距离 :param output: 输出的图片文件 :return: """ # 图片拼接 img1, img2 = Image.open(png1), Image.open(png2) size1, size2 = img1.size, img2.size # 获取两张图片的大小 joint = Image.new('RGB', (size1[0], size1[1]+size2[1]-size)) # 创建一个空白图片 # 设置两张图片要放置的初始位置 loc1, loc2 = (0, 0), (0, size1[1] - size) # 分别放置图片 joint.paste(img1, loc1) joint.paste(img2, loc2) # 保存结果 joint.save(output)
JS = { '滚动到页尾': "window.scroll({top:document.body.clientHeight,left:0,behavior:'auto'});", '滚动到': "window.scroll({top:%d,left:0,behavior:'auto'});", } # 获取body大小 body_h = int(driver.find_element_by_xpath('//body').size.get('height')) # 计算当前页面截图的高度 # (使用driver.get_window_size()也可以获取高度,但有误差,推荐使用图片高度计算) current_h = Image.open('result.png').size[1] image_list = ['result.png'] # 储存截取到的图片路径
for i in range(1, int(body_h/current_h)): # 1. 滚动到指定锚点 driver.execute_script(JS['滚动到'] % (current_h * i)) # 2. 截图 driver.save_screenshot(f'test_{i}.png') join_images('result.png', f'test_{i}.png') # 处理最后一张图 driver.execute_script(JS['滚动到页尾']) driver.save_screenshot('test_end.png') # 拼接图片 join_images('result.png', 'test_end.png', size=current_h-int(body_h % current_h)
运行之后的结果为:
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理
21天更文挑战,赢取价值500元大礼,还有机会成为签约作者!